Index
Index
Struttura dati costruita sopra al testo, per velocizzare la ricerca. Utilizzata quando la collezione di testi è grande e semi statica (aggiornata a intervalli regolari ma consoni).
Tecniche di indicizzazione
Ci sono più tecniche di indicizzazione, tra cui:
- inverted index
- suffix array
- signature file
Per scegliere la più adatta si tiene conto del costo di ricerca, del peso e del costo di costruzione e aggiornamento degli stessi indici.
Inverted index
Word oriented. Composto da vocaboli e occorrenze ed è la miglior scelta al momento.
Suffix array
Più veloce per queri di frasi e altri tipi di query meno comuni, ma molto più complessi da generare e mantenere.
Signature file
Basato sull’hash delle parole.
Notazioni!
- n: dimensione del database di testo
- m: lunghezza del pattern
- M: dimensione di memoria disponibile
Ricerca sequenziale (o online)
È la ricerca di un pattern in un testo che non ha subito preprocessing. Si può eseguire quando il testo è piccolo, ed è l’unica soluzione se la collezione di testi è volatile o se non si ha spazio per un indice.
Matrice di incidenza
| Antony and Cleopatra | Julius Caesar | The tempest | Hamlet | Othello | Macbeth | |
|---|---|---|---|---|---|---|
| Antony | 1 | 1 | 0 | 0 | 0 | 1 |
| Brutus | 1 | 1 | 0 | 1 | 0 | 0 |
| Caesar | 1 | 1 | 0 | 1 | 1 | 1 |
| Calpurnia | 0 | 1 | 0 | 0 | 0 | 0 |
| Cleopatra | 1 | 0 | 0 | 0 | 0 | 0 |
| mercy | 1 | 0 | 1 | 1 | 1 | 1 |
| worser | 1 | 0 | 1 | 1 | 1 | 0 |
Ogni parola ha quindi un vettore di 0 e 1 associato. Per rispondere ad una query boolena, si possono effettuare operazioni booleane tra questi vettori.
Matrice di incidenza
La matrice di incidenza è poco scalabile, e non va bene per grandi collezioni di documenti.
Costruzione di un indice
Basic indexing
Data una collezione di documenti, si tokenizza ogni documento e si converte in una sequenza di termini. Per ogni token si aggiunge quindi il documento alla posting list.
Molto semplice su piccole collezioni di documenti, ma inizia ad essere complesso quando i documenti e il vocabolario aumentano di dimensione.
Trie based
Questo metodo implica l’utilizzo di un Trie. Tutti i vocaboli conosciuti fino ad ora sono mantenuti in un trie. Si parte con il leggere parola per parola di un testo. Si cerca quella parola nel trie, e se non si trova, si aggiunge alla struttura con una lista vuota di occorrenze. Se la parola invece esiste, si aggiunge la nuova posizione alla fine della lista delle occorrenze. Una volta che tutti i vocaboli sono stati processati, il trie viene scritto su disco con la lista delle occorrenze.
Merging lists
L’indicizzazione base fallisce non appena si finisce la memoria. Per ovviare a questo problema, si salva una parte di inverted list su disco quando supera una certa dimensione. Si resetta l’indice in memotia e si ricomincia. Quando si finisce, si fa il merging degli indici parziali.
Ovviamente gli indici parziali devono essere scritti in memoria in modo da favorire il merging.
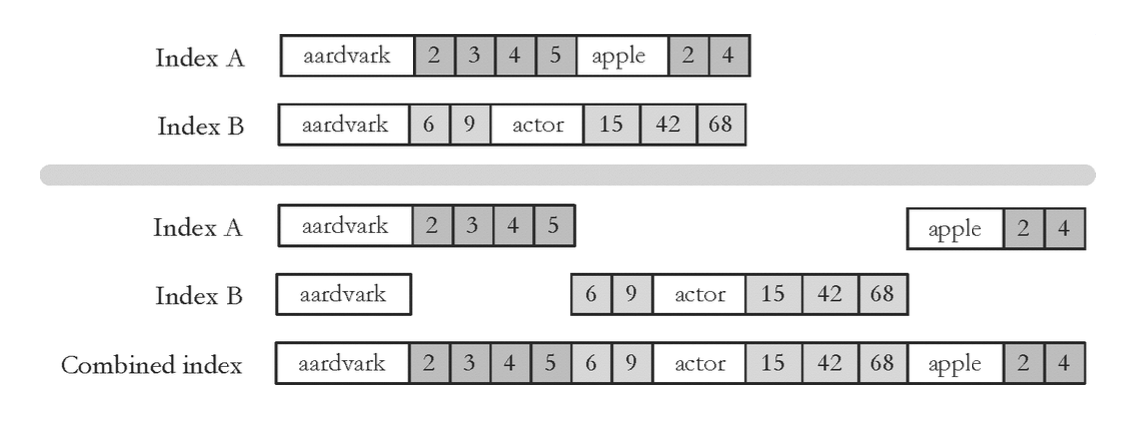
Dividere l’indice in due file
Dividere l’indice in due file permette di tenere in memoria il vocabolario a tempo di ricerca.
- Le posting list sono salvate in celle contigue.
- il vocabolario è salvato e per ogni termine il numero di documenti ad esso associati e i puntatori al file di posting list è incluso
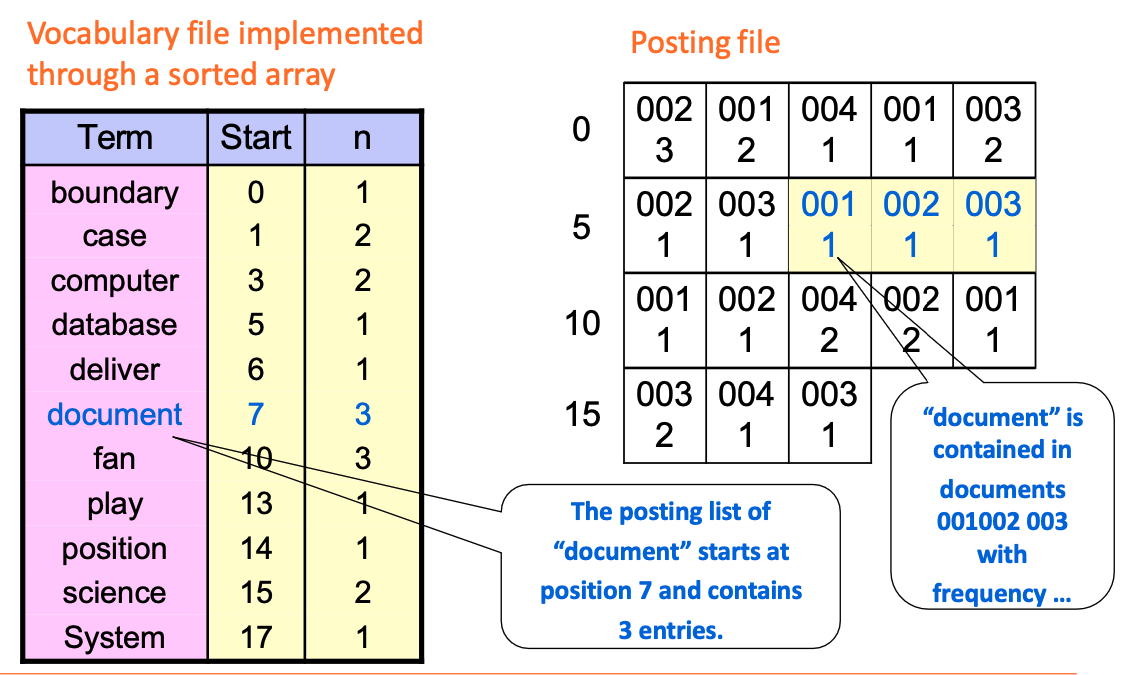
Strutture di file vocabolario
Per accelerare il processo di ricerca, le strutture dati migliori sono:
- sorted array (in ordine lessicografico): ricerca (binary search) veloce, ma costoso da aggiornare
- tree: pesa di più rispetto ad un sorted array
- Trie
- Hash