Inverted index
Struttura usata per fare l’indexing di una collezione di testi con l’obiettivo di velcizzare la ricerca. È composta da due elementi:
Vocabolario
Set di tutte le parole presenti nel testo, e per ognuna di esse la document frequency, ovvero il numero di documenti in cui è presente.
Occorrenze (Posting List)
Per ogni parola è presente una lista di posizione dove il termine compare. Ci sono due modi per organizzare questa lista:
- Document based, una lista di documenti con la corrispondente term frequency, ovvero quante volte il termine compare nel documento.
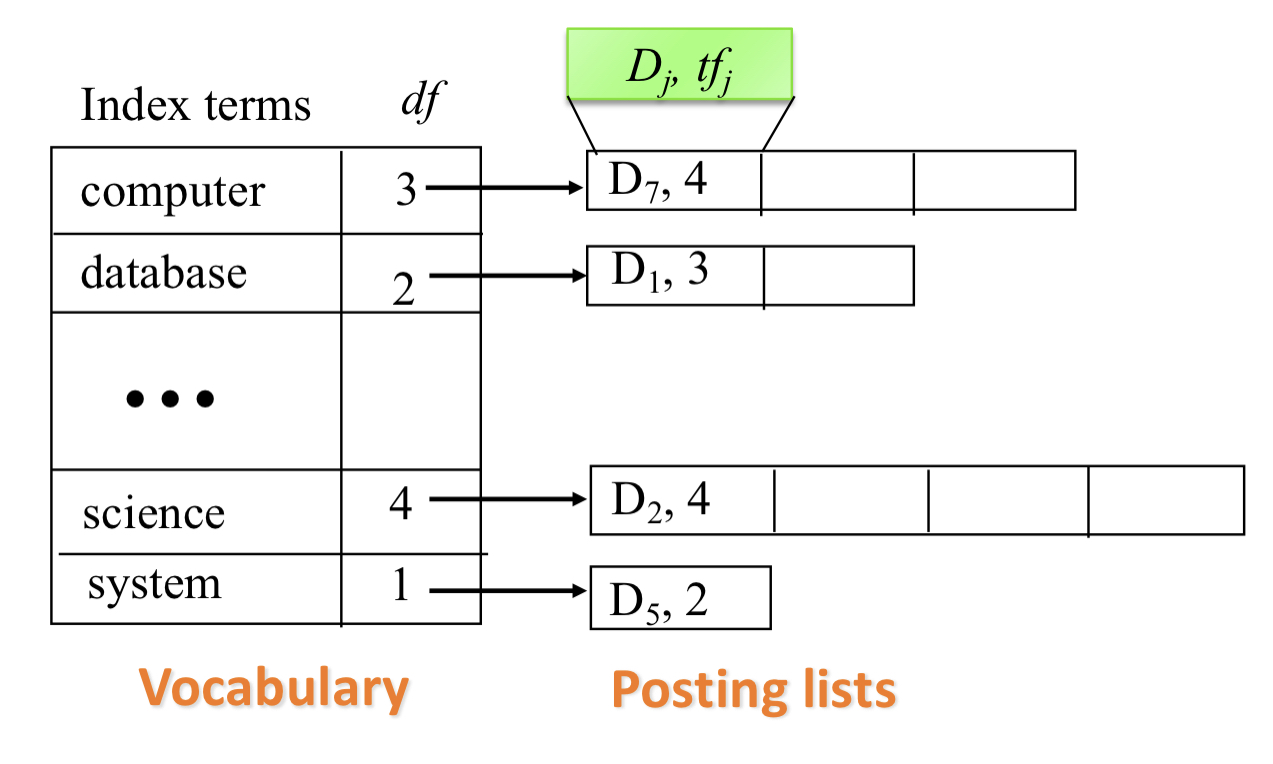
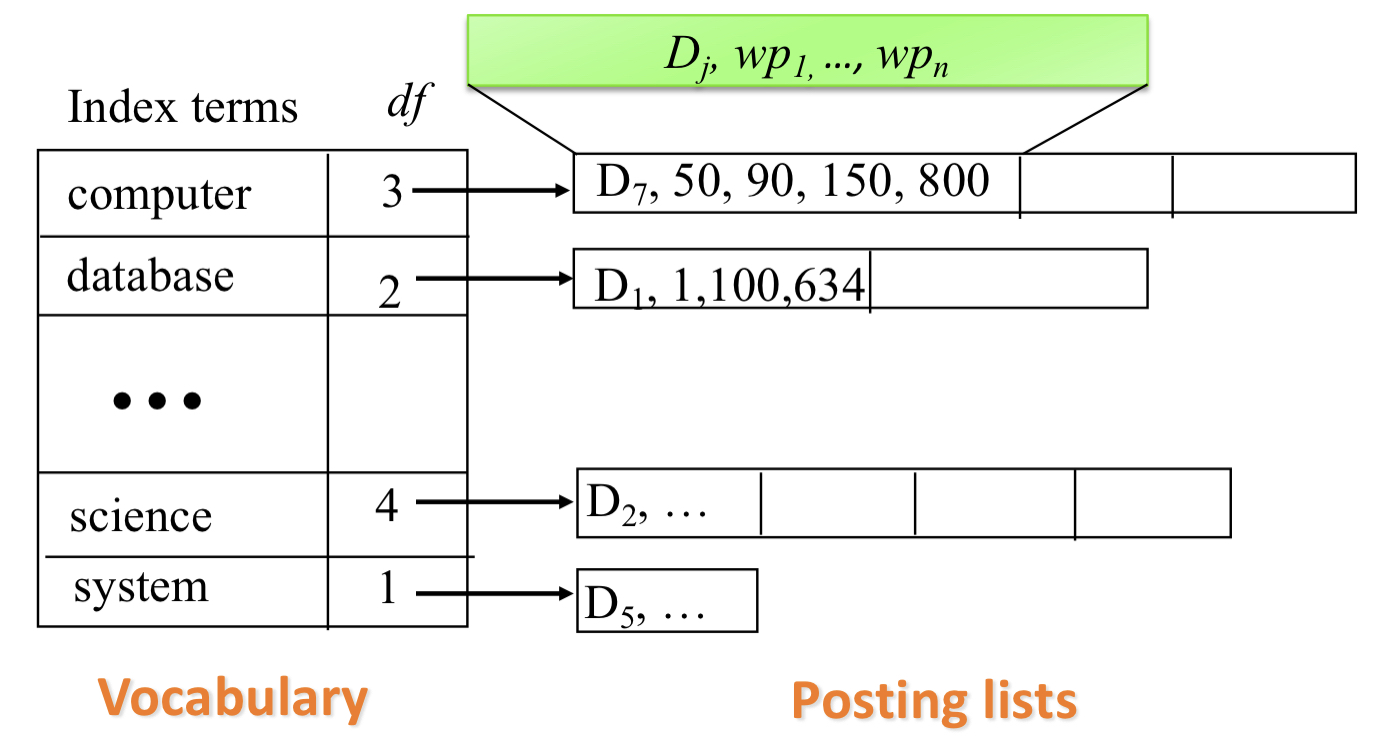
- Word based, una lista di documenti con la corrispondente posizione della parola. In questa maniera si facilita la Proximity search.
Spazio richiesto
Questa struttura richiede spazio sia per il vocabolario che per la posting list.
Per il vocabolario serve poco spazio, dal momento che sarà sicuramente più piccolo del numero di documenti.
Heaps law
Il vocabolario cresce come dove (solitamente )
Questo si può ridurre ancora con lo Stemming e altre tecniche di normalizzazione.
Per la posting list, invece, si necessita di molto più spazio.
- Word-based: , che è circa il 40% delle dimensioni del testo se le stopword sono state eliminate, l’80% altrimenti.
- Document-based: tra il 20% e il 40% delle dimensioni del testo.
Come si costruisce un indice
flowchart TD
result --> I
subgraph schema
A(Documenti) --> B(Tokenizer) --> C(Linguistic modules) --> D(Indexer)
end
subgraph example
E(Friends, Romans, countrymen) --> F(Friends Romans Countrymen) --> G(friend roman countryman) --> result
end
subgraph result
direction LR
I[friend] ==> L["2|4"]
M[roman] ==> N["1|2"]
O[countryman] ==> P["13|16"]
end
Tutto il vocabolario fino ad ora è contenuto in un trie. Per costruirlo si esegue:
- Lettere ogni parola del testo
- Ricerca della parola nel trie
- Se la parola non è presente si aggiunge con una lista vuota
- Se la parola è presente la nuova posizione è aggiunta alla fine della posting list
- Quando il testo è finito, il trie è scritto su disco assieme alla lista di occorrenze
Complessità:
operazioni per ogni carattere durante la ricerca operazioni per inserire la posizione nella lista di occorrenze operazioni per tutto il processo
title: Attenzione
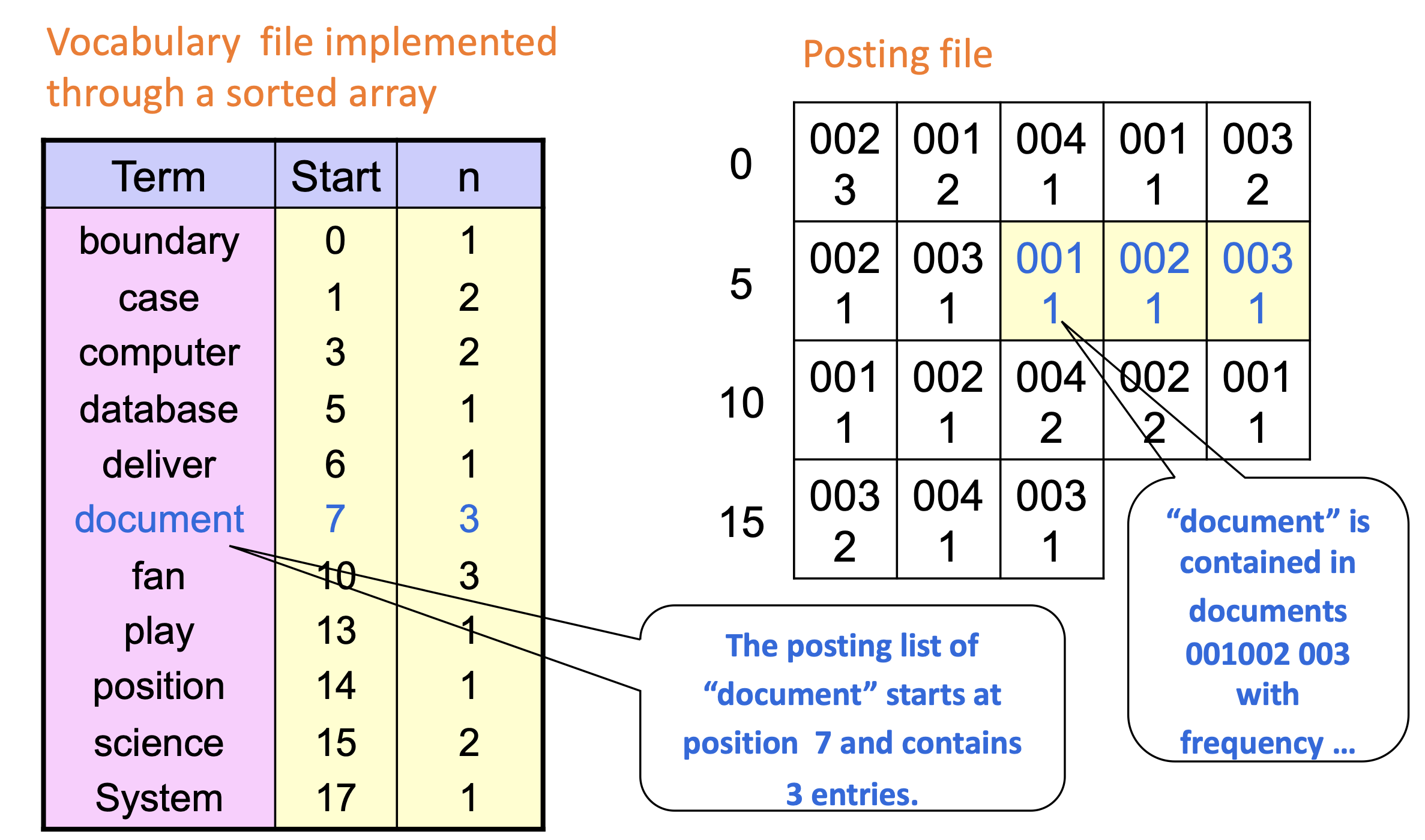
Si può dividere l'indice su due file.Dividere l’indice su due file
Dividerlo su più file rende possibile tenere in memoria il vocabolario, e quindi rendere la ricerca ancora più veloce.
Le liste del posting file sono salvate in celle contigue.
Il vocabolario viene salvato con il numero dei documenti associati, e il puntatore alla posting list.