- Analisi lessicale
- Eliminazione delle stopwords
- Stemming
- [[#Stemming#Come giudicare uno stemmer|Come giudicare uno stemmer]]
Preprocessing
Preprocessing
Procedura che trasforma un documento in un insieme di index terms
- Analisi lessicale del testo
- Eliminazione delle stop words
- Stemming delle parole restanti
- Selezione degli index terms
- Costruzione delle strutture di categorizzazione dei termini Rende disponibile l’espansione della query originale con termini collegati
Analisi lessicale
Analisi lessicale
Processo di conversione di uno stream di caratteri in uno stream di token
In pratica produce dei token che possono essere utilizzati come index terms.
Possibili token:
- cifre Solitamente non utilizzati come otken perché molto vaghi. Ma in alcuni casi importanti (vitamina B6, 510A.C., … serve una procedura di analisi lessicale più avanzata)
- trattini Si deve adottare una regola generale, e specificarre le eccezioni caso per caso. “State-of-di-art” senza diventa “state of the art” che va bene, mentre “MS-DOS” diventerebbe “MS DOS”, che non ha nessun significato
- punteggiatura Viene rimossa tutta. Bisogna stare attenti però ad alcuni casi particolari, come ad esempio “val.id” diventerebbe “valid”, cosa che non c’entra nulla
- letter case Tutti i casi vengono rimossi. Si può perdere la semantica.
Eliminazione delle stopwords
Eliminazione delle stopwords
Filtraggio di parole con un valore discriminante molto basso. Ad esempio: a, the, this, when…
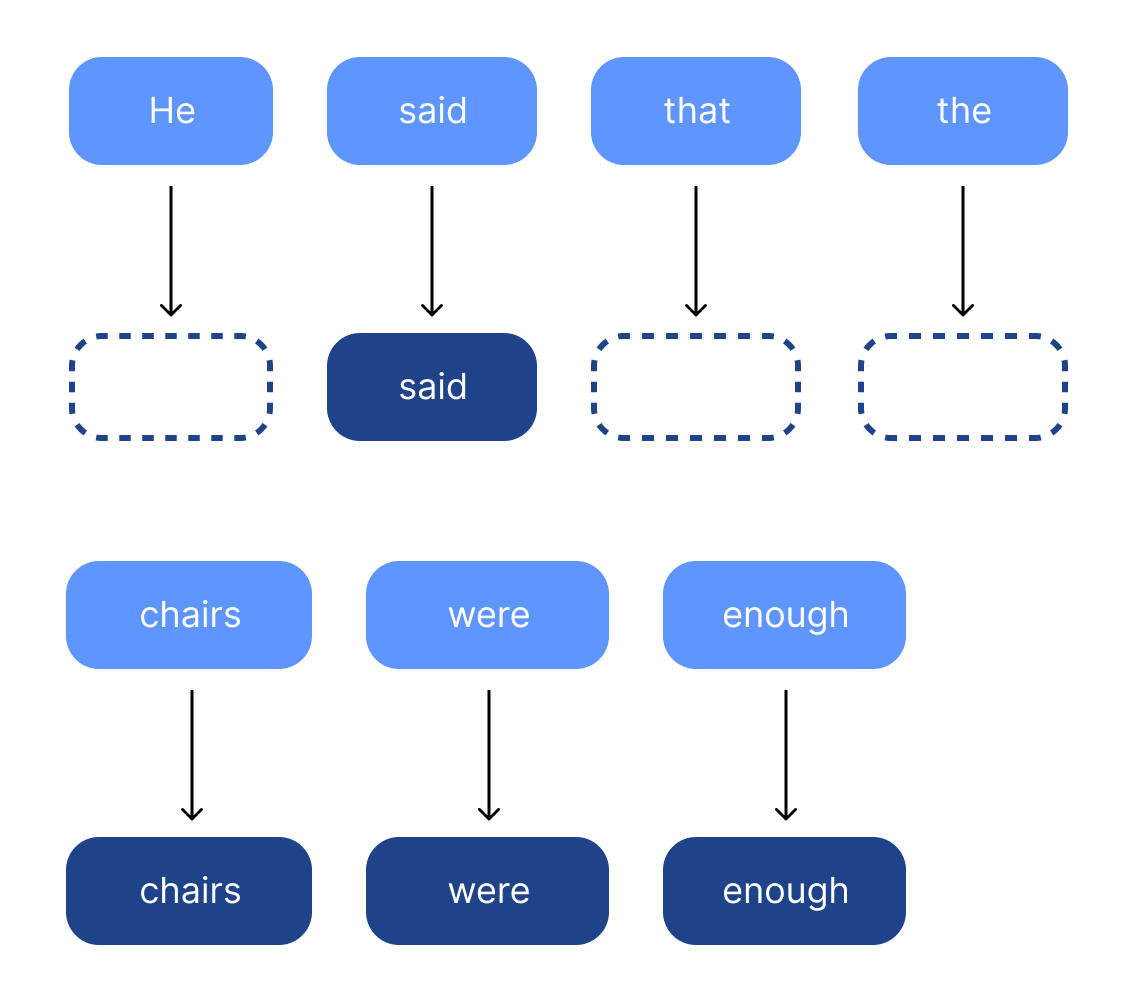
Una parola troppo frequente non è importante per la ricerca. Andrebbe a falsare i risultati. E questo riduce anche le dimensioni dell’indice.
Per rimuovere le stopwords si può agire in due modi:
- esaminare l’output dell’analizzatore sintattico e rimuovere le parole non necessarie. Si trovano i problemi di ricerca degli elementi in una lista
- eliminarle direttamente nell’analizzatore sintattico, che è più veloce
Stemming
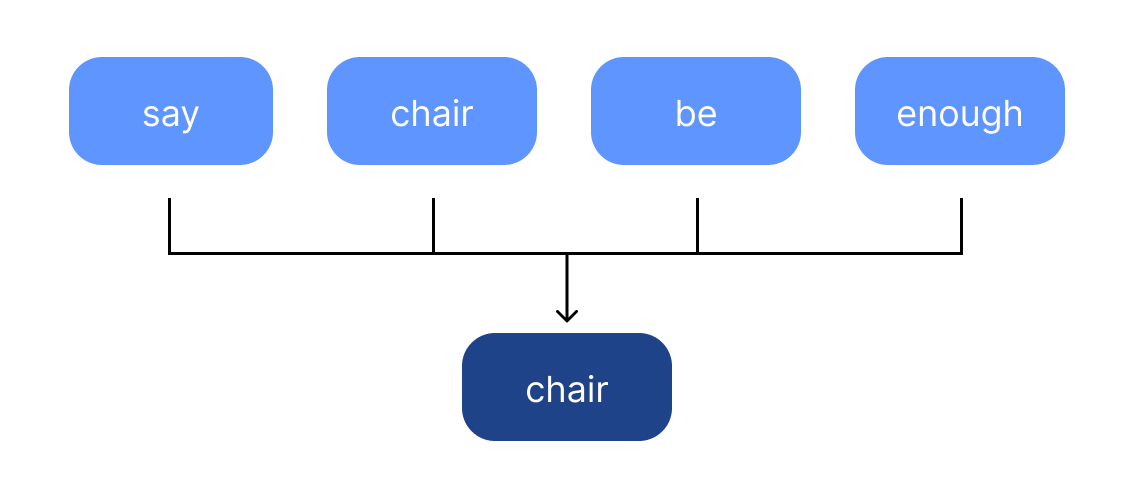
Stemming
Rende disponibile la ricerca di varianti morfologiche di tutti i termini.
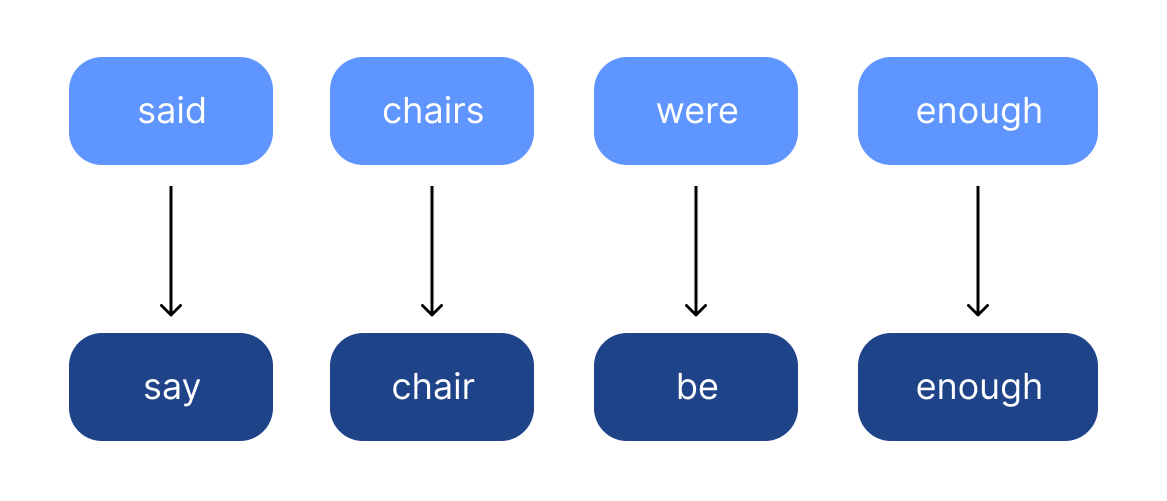
Stem: parte della parola rimanente che rimane dopo la rimozione di prefissi e suffissi. Stemmer: tool che effettua la stemmatizzazione
Lemma: forma base o forma di dizionario di una parola Lemmatizer: tool che effettua la lemmatizzazione
Come giudicare uno stemmer
Uno stemmer può fare:
- understemming: rimuovere troppo poco
- overstemming: rimuovere troppo
Selezione degli index terms
Index terms
Non tutte le parole sono equivalenti dal punto di vista di rappresentazione della semantica di un documento.
La selezione manuale dei termini da indicizzare è fatta da specialisti. La selezione automatica si basa sul fatto che la maggior parte della semantica di un documento è basata sui nomi. Per identificare automaticamente i nomi si usano Parser e tagger.
Se non è indicizzato, un documento è solo una bag of words, ovvero un insieme non strutturato di parole.